

As hyperscalers increasingly prioritize real-time AI inference at unprecedented scale in 2026, one of the semiconductor industry's most ambitious challengers is finally approaching the public markets. According to reports from Bloomberg and Reuters, Cerebras Systems has confidentially filed for a Nasdaq IPO that could value the company between $26 billion and $40 billion, potentially making it one of the largest semiconductor listings of the AI era.
The offering arrives at a pivotal moment for the AI infrastructure market. While training workloads continue to expand, hyperscalers and frontier-model developers are increasingly focused on inference efficiency, latency, and serving costs as AI agents and real-time reasoning systems scale toward mass deployment. Cerebras is positioning itself as one of the boldest alternatives to the conventional GPU cluster architecture dominated by NVIDIA.
Cerebras' Bet on Wafer-Scale Inference
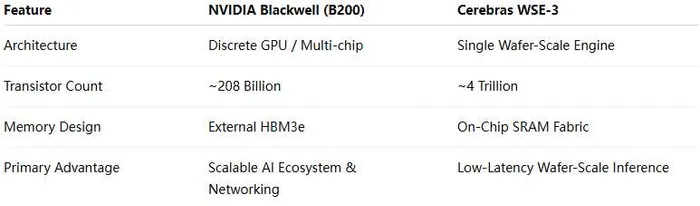
At the center of Cerebras' investment thesis is its attempt to address one of the most persistent bottlenecks in modern AI systems: the "memory wall." While NVIDIA's Blackwell B200 represents one of the most advanced discrete GPU architectures ever built — integrating roughly 208 billion transistors — its architecture still relies on external HBM3e memory and high-speed interconnects to scale across clusters.
By contrast, Cerebras' WSE-3 (Wafer Scale Engine 3) takes a radically different approach. Rather than splitting workloads across many discrete processors, the company places an entire AI compute fabric on a single wafer-scale chip containing approximately 4 trillion transistors.
While NVIDIA's Blackwell architecture delivers approximately 8 TB/s of external HBM memory bandwidth per GPU, Cerebras emphasizes the massive internal bandwidth enabled by its wafer-scale SRAM architecture. According to recent analysis from Morgan Stanley Research, the company claims aggregate on-chip bandwidth in the petabytes-per-second range, reducing dependence on interconnect-heavy GPU clusters and minimizing latency associated with moving data between accelerators.
Cerebras has demonstrated materially lower inference latency on selected large-language-model workloads, although direct comparisons vary significantly depending on batch size, context length, and serving configuration. The company argues that keeping entire models on-chip may offer significant advantages for real-time AI inference, particularly as next-generation models demand increasingly larger context windows and lower response latency.
The OpenAI Partnership and the Inference Arms Race
The growing industry focus on inference has helped Cerebras gain visibility among frontier AI developers. The Information previously reported that OpenAI expanded its partnership with Cerebras to secure large-scale inference capacity through 2028.
While the precise economics of the agreement remain undisclosed, industry estimates suggest the arrangement could ultimately be worth tens of billions of dollars over its duration. More importantly, the partnership signals that leading AI labs are increasingly seeking diversification beyond NVIDIA-centric infrastructure stacks as inference demand accelerates.
For AI developers operating large-scale agentic systems, inference economics are becoming just as important as training performance. Lower latency, reduced networking overhead, and improved energy efficiency could emerge as critical competitive differentiators as AI usage scales globally.
Architecture vs. Ecosystem
Ultimately, the Cerebras–NVIDIA rivalry reflects a broader debate shaping the future of AI infrastructure: specialized wafer-scale compute versus ecosystem-driven GPU architectures. While NVIDIA maintains a powerful competitive moat through CUDA, NVLink, and hyperscale software integration, Cerebras Systems is betting that tightly integrated wafer-scale inference can deliver superior latency and efficiency for next-generation AI workloads. Rather than directly replacing GPUs, Cerebras may ultimately emerge as a specialized inference platform serving a narrower — but potentially enormous — segment of the AI compute market.